Today I’ve been kicking around the ICT office with Alex, figuring out how to make Jenkins (our wonderful CI server) build and publish the latest version of the CWD with all the bells and whistles like compilation of CSS using LESS, minification, validation of code and so-on. As part of this we managed to fix a couple of bits and pieces which had been bugging me for a while, namely the fact that GitHub commit notifications weren’t working properly (fixed by changing the repository URI in the configuration) and the fact that Campfire integration wasn’t working (fixed by hitting it repeatedly with a hammer).
This brought me to thinking about how our various things tie in together, so I set about charting a few of them up. After a while I realised the chart had basically expanded into a complete flowchart of the various tools and processes that hang together to keep the code flowing in a steady stream from my brain – via my fingers – into an actual deployment on the development server. Since it may be of interest to some of you, here’s a pretty picture:
This is (approximately) the toolchain I currently use for Orbital, including rough details of what is being passed around
The beauty of this is that the vast majority of the lines happen completely by themselves — I get to spend my days living in the small bubble of my local development server and dipping in and out of Pivotal Tracker to update stories. The rest is magically happening as I work, and the constant feedback through all our monitoring and planning systems (take a look at SplendidBacon for an epic high-level overview) means that the rest of the project team and any project clients can see what’s going on at any time.
We intend to re-use and develop some of the underlying tools we have built to provide an institution-wide service for the ingest, description, preservation and dissemination of research data, which is informed by the OAIS reference model.
My first encounter with OAIS was about seven years ago, when I was designing a digital archive for Amnesty International’s image, film and video archives. If you begin to do any design work in the digital archiving domain, you come across the OAIS model very quickly. It is the standard and though somewhat daunting, when you get your teeth into it, you realise that it does an excellent job of describing what any decent digital archive should be doing anyway.
The mistake to make with OAIS is looking at the model and thinking that you have to create a system that is designed in such a way, rather than functions in such a way. The OAIS standard is a tool that allows Archivists, Designers and Developers to share a common language when discussing and planning the implementation of a digital archive and what that archive should do, not how it should be designed.
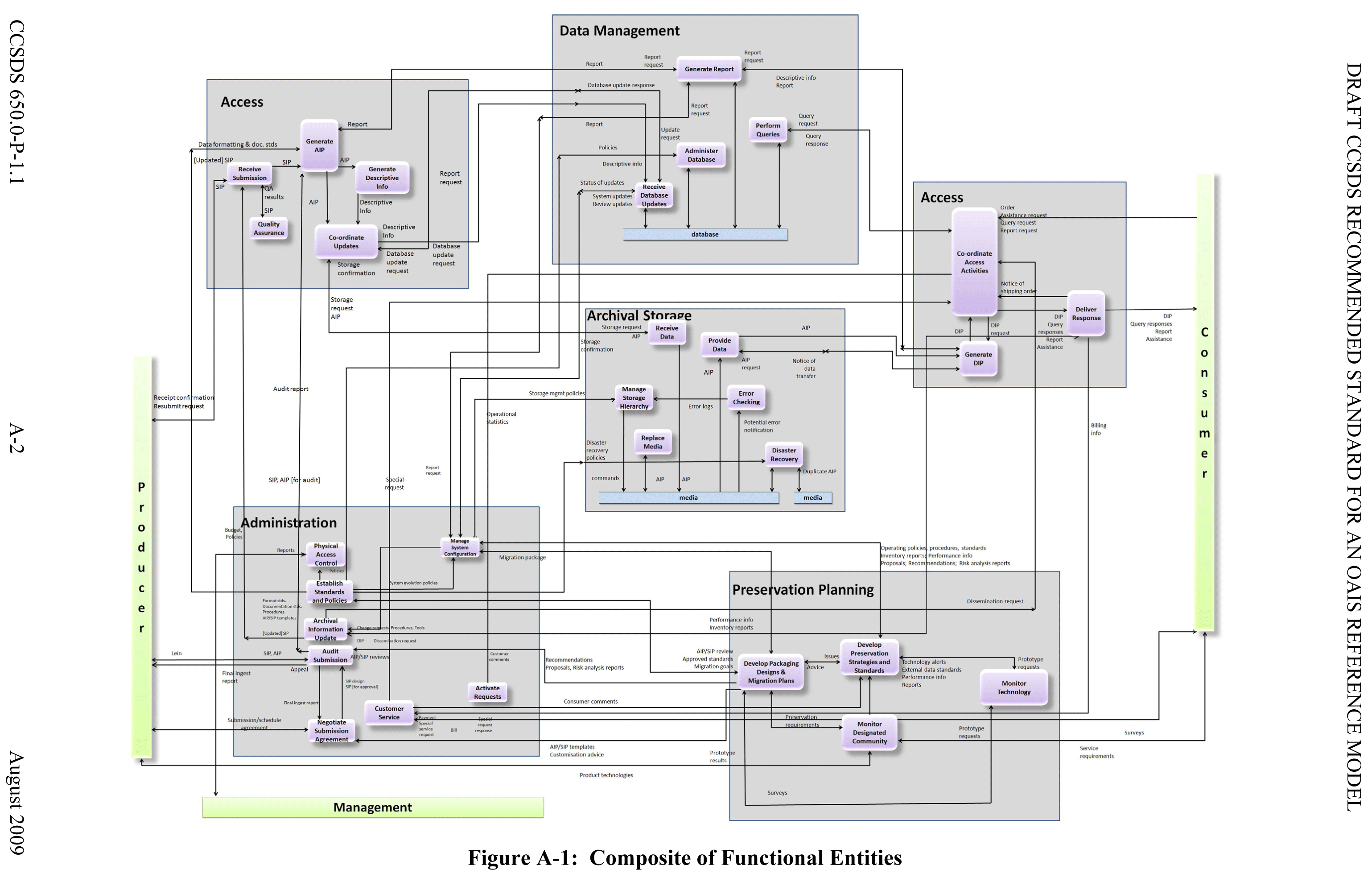
Here is the high-level OAIS model. (Here is the full, composite model).
OAIS Functional Entities
Here is a high-level model of Orbital.
Orbital design
They’re very different because they should be. Remember, the first is a functional model, the second is a logical model of Orbital’s server requirements.
Here’s another model I published recently relating to building staff profiles.
Building staff profiles
The task ahead of the Orbital Team is to consider how our on-going designs like these two above, relate to the OAIS functional model. For example, the staff profile diagram (which is not simply an abstract model, but a retrospective design document) tells us where some of the OAIS Submission Information Package (SIP) information will be derived from. When a ‘Producer’ (i.e. a Researcher) signs in to Orbital and uploads a dataset, that content and the information we know from their university profile, as well as further information that they provide, constitutes the SIP.
As I was reading around the OAIS standard recently, I came across a nice piece of work done by a collaborative project between Cornell and Göttingen State universities. Their MathArc project was run using the XP agile project management methodology and as part of their development process, they broke down the OAIS reference model into a deck of 33 cards and tackled each one as a specific iteration. You can download the cards, here [.doc].
Although we’re not planning on 100% OAIS ‘compliance’ during this pilot stage of the Orbital project, it is our intention that Orbital is informed by the OAIS standard and these cards provide a useful and provocative set of functional requirements that we have added to our project tracker. Nick’s currently working on authentication and security for Orbital, or rather, card #3 ‘Provide Security Services’:
Protect sensitive information in the system, including authentication, access control, data integrity, data confidentiality, and non-repudiation services.
Cards #1 and #2 (‘Provide O/S Services’ & ‘Provide Network Services’) are requirements that go beyond the Orbital project itself and are largely met by the wider IT infrastructure that we’re working in at Lincoln. However, our work on ‘piloting the cloud‘ also addresses issues relating to the operating environment and networking of our future RDM infrastructure.
Nick and I met a couple of weeks ago to look at the OAIS model in detail and consider it in light of what we’re beginning to implement. As we’d hope, the high-level stuff you see in the diagram at the top of this post is easy to ‘tick off’. You couldn’t really say you were building an infrastructure to manage research data if you weren’t clear on the basic functional entities of OAIS. The lower-level components of the OAIS standard are where the work gets interesting and more demanding, and where the deck of cards is useful. Along the way, we’ll be creating diagrams like those above to show how we’re iteratively addressing the OAIS standard so that by the end of the project, we should have a model of our own that maps reasonably well onto the OAIS composite model.
I’d be very interested to hear from other MRD projects that are looking at the OAIS standard in detail, as well as people from earlier projects that have been through this process before. I know there have been a number of such efforts in the JISC community. A couple of the documents I found useful were Alex Ball’s Briefing Paper and Julie Allinsons’s OAIS as a reference model for repositories. The paper I remembered from my time at Amnesty is Brian Lavoie’s Introductory Guide. If you’re new to OAIS, I’d recommend that you at least read Lavoie’s report before tackling the full OAIS standard document (PDF).
Did you know that you can watch our user requirements gathering and see how Orbital development is progressing by following our Github and Pivotal Tracker activity? Here are the key links:
Updates are also merged in a single stream of activity on Splendid Bacon.
Internally, we watch all of this activity through Campfire, thanks to Hubot and a bit of plumbing. Commits to Github, new stories and other activity on Pivotal Tracker, fire off API notifications which Hubot (‘Zakia’), delivers to Campfire. Here’s what this afternoon’s activity looked like.
Watching Orbital progress on Campfire, using Hubot (Zakia)
Using a mixture of friendly APIs, asynchronous messaging and a chat bot provides us with a handy method of keeping track of what’s going on when we can’t all be in the same room.
In December, colleagues in the Web Team (who manage the corporate web site in the Department of Marketing and Communications) approached a few of us about building a tool to allow staff to edit their profile for the new version of the lincoln.ac.uk website. We suggested that much of the work was already done and it just needed gluing together. Yesterday we met with the Web Team again to tell them that our part of the work is pretty much complete. Here’s how it works.
Quick sketch of profile building at Lincoln
This requires a bit of explanation, but let me tell you, it’s the holy grail as far as I’m concerned and having this in place brings benefits to Orbital and any other new application we might develop. Here’s a clearer rendering.
Building staff profiles
The chart above strips out the stuff around authentication that you see in the bottom right of the whiteboard photo. That’s for another post – something Alex is better placed to write.
Information about staff at the university starts with the HR database. This feeds the Active Directory, which authenticates people against different web services. Last year, Nick and Alex pulled this data into Nucleus, our MongoDB datastore, and with it built a new, slick staff directory. Then they started bolting things on to it, like research outputs from the repository and blog posts from our WordPress/BuddyPress platform. To illustrate what was possible, they started pulling information from my BuddyPress profile, which I could edit anytime I wanted to. It got to the point where I started using my staff directory link in my email signature because it offered the most comprehensive profile of me anywhere on a Lincoln website.
By the time we first met with the Web Team about the possibility of helping them with staff profiles, Alex and Nick had 80% of the work already done. What remained was to create a richer number of required fields in BuddyPress for staff to edit about themselves and a scheduled XML dump for the Web Team to wrangle into their new templates on www.lincoln.ac.uk.
So the work is nearly done. The XML file is RDF Linked Data, which means that we have a rich aggregation of staff information and some simple relationships, feeding the Staff Directory, being refreshed every three hours and then being output either as HTML, JSON or RDF/XML.
For the Orbital project, all this glue is invaluable. When staff login to Orbital (Nick’s working on this part right now), we’ll already know who they are, which department they work in, what research outputs they’ve deposited in the institutional repository, what their research interests are, what projects they’re working on, the research groups they’re members of, their recent awards and grants, and the keywords they’ve chosen to tag their profile with. It’s our intention that with some simple AI, we’ll be able to make Orbital a space where Researchers find themselves in an environment which already knows quite a bit about their work and the context of the research they’re undertaking. Once Orbital starts collecting specific staff data of its own, it can feed that back into Nucleus, too.
This reminds me of our discussion last month with Mansur Darlington of the ERIM/REDm-MED project. Mansur stressed the importance of gathering data about the context of the research itself, emphasising that without context, research data becomes increasingly meaningless over time. Having rich user profiles in Orbital and ensuring that we record data about the Researcher’s activity while using Orbital, should help provide that context to the research data itself.
Orbital, therefore, becomes an infrastructure not only for storing and managing research data, but also a system for storing and managing data about the research itself.
One of the interesting things about Orbital is its use of an API-driven development approach. In traditional, API-less applications your end-to-end system would look something like this:
The only way to interact with this application is to either be a user, or pretend to be one.
This is all well and good if the only thing you want to be able to interact with your application is a real user, but it’s increasingly a bad idea. Users can interact with your application as intended, but should a machine want to get at your data (which may happen for any one of a hundred reasons) they’ve got to muck about pretending to be a user and scraping data. Everybody is building with APIs nowadays, and if you aren’t then you’re going to be left behind, cold and frightened, in a world which no longer subscribes to the notion that monolithic software can stand on its own and provide useful functionality.
So the next step is to bolt on an API.
APIs like this are notorious for only exposing part of the functionality of an application.
This is the most common form of API around, and consists of a ‘second view’ on the data and functionality of an application. This is a massive step forwards and makes lives much, much easier in most cases. The only downside is that it’s very easy for this kind of API to provide a ‘bare bones’ functionality, such as only providing a list of items when the ‘real’ user interface lets you not only view the list but also edit its contents. It’s better than nothing but not ideal, which is why Orbital is taking the next step:
In an API-driven model the API is the only way to interface with the application
Under this design the API is the only way to interface with the data and functionality of the system. If a user wants to access it they must go through an intermediary to translate their wishes into API calls, and the results back into a nicely human readable form. The plus side is that any other consumer of the service is free to interact with the application on exactly the same terms as the ‘official’ frontend, providing that it has been granted those permissions. As far as Orbital Core (our actual application) is concerned there is no functional difference between Orbital Manager (our frontend) and an application that a researcher has hacked together to give themselves an easier time inputting data — they are subject to the exact same access controls, restrictions, sanity checking and limitations.
This means that every time we want to build user-facing functionality we have to stop, look at our APIs and work out where the functionality belongs. This also has the added benefit of making it essential to fully document our APIs for our own sanity, as well as ensuring that we have lightweight data transfer and rock-solid error handling baked right in.
The downside is that we have to double up on some bits of development, writing both the Core and Manager sides. It can also lead to the usual frustrations you get when trying to communicate with APIs, but on the plus side we have the ability to change both ends for the better.
Know of any other API-driven development in the fields of higher education or research data management? We’d love to hear about them, so that we can try to make our APIs as compatible as possible and improve interoperability. Drop us a note in the comments.









{kind=link}