In the Orbital project bid, I wrote,
We intend to re-use and develop some of the underlying tools we have built to provide an institution-wide service for the ingest, description, preservation and dissemination of research data, which is informed by the OAIS reference model.
My first encounter with OAIS was about seven years ago, when I was designing a digital archive for Amnesty International’s image, film and video archives. If you begin to do any design work in the digital archiving domain, you come across the OAIS model very quickly. It is the standard and though somewhat daunting, when you get your teeth into it, you realise that it does an excellent job of describing what any decent digital archive should be doing anyway.
The mistake to make with OAIS is looking at the model and thinking that you have to create a system that is designed in such a way, rather than functions in such a way. The OAIS standard is a tool that allows Archivists, Designers and Developers to share a common language when discussing and planning the implementation of a digital archive and what that archive should do, not how it should be designed.
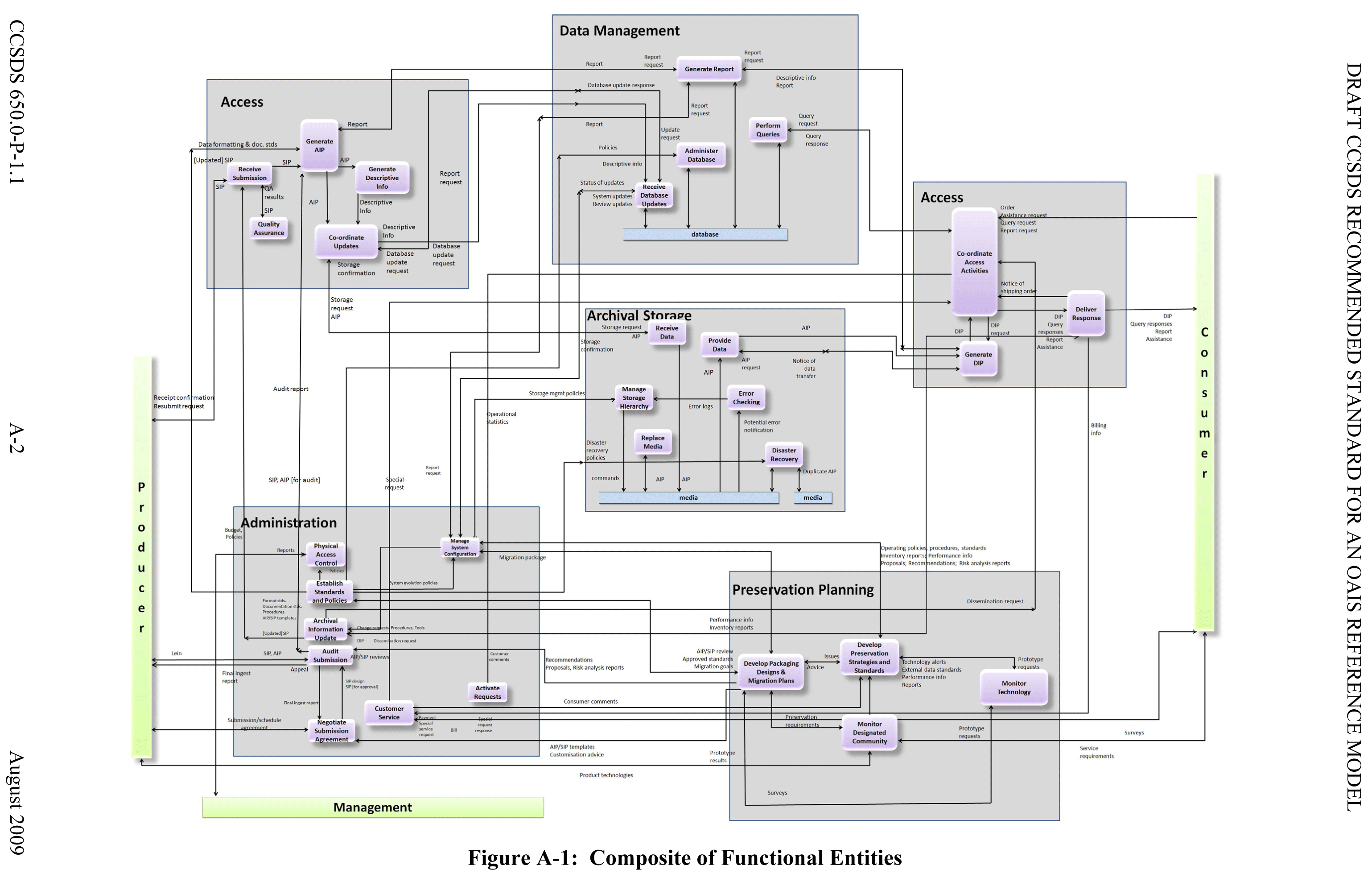
Here is the high-level OAIS model. (Here is the full, composite model).

Here is a high-level model of Orbital.

They’re very different because they should be. Remember, the first is a functional model, the second is a logical model of Orbital’s server requirements.
Here’s another model I published recently relating to building staff profiles.

The task ahead of the Orbital Team is to consider how our on-going designs like these two above, relate to the OAIS functional model. For example, the staff profile diagram (which is not simply an abstract model, but a retrospective design document) tells us where some of the OAIS Submission Information Package (SIP) information will be derived from. When a ‘Producer’ (i.e. a Researcher) signs in to Orbital and uploads a dataset, that content and the information we know from their university profile, as well as further information that they provide, constitutes the SIP.
As I was reading around the OAIS standard recently, I came across a nice piece of work done by a collaborative project between Cornell and Göttingen State universities. Their MathArc project was run using the XP agile project management methodology and as part of their development process, they broke down the OAIS reference model into a deck of 33 cards and tackled each one as a specific iteration. You can download the cards, here [.doc].
Although we’re not planning on 100% OAIS ‘compliance’ during this pilot stage of the Orbital project, it is our intention that Orbital is informed by the OAIS standard and these cards provide a useful and provocative set of functional requirements that we have added to our project tracker. Nick’s currently working on authentication and security for Orbital, or rather, card #3 ‘Provide Security Services’:
Protect sensitive informatio
n in the system, including authentica tion, access control, data integrity, data confidenti ality, and non-repudi ation services.
Cards #1 and #2 (‘Provide O/S Services’ & ‘Provide Network Services’) are requirements that go beyond the Orbital project itself and are largely met by the wider IT infrastructure that we’re working in at Lincoln. However, our work on ‘piloting the cloud‘ also addresses issues relating to the operating environment and networking of our future RDM infrastructure.
Nick and I met a couple of weeks ago to look at the OAIS model in detail and consider it in light of what we’re beginning to implement. As we’d hope, the high-level stuff you see in the diagram at the top of this post is easy to ‘tick off’. You couldn’t really say you were building an infrastructure to manage research data if you weren’t clear on the basic functional entities of OAIS. The lower-level components of the OAIS standard are where the work gets interesting and more demanding, and where the deck of cards is useful. Along the way, we’ll be creating diagrams like those above to show how we’re iteratively addressing the OAIS standard so that by the end of the project, we should have a model of our own that maps reasonably well onto the OAIS composite model.
I’d be very interested to hear from other MRD projects that are looking at the OAIS standard in detail, as well as people from earlier projects that have been through this process before. I know there have been a number of such efforts in the JISC community. A couple of the documents I found useful were Alex Ball’s Briefing Paper and Julie Allinsons’s OAIS as a reference model for repositories. The paper I remembered from my time at Amnesty is Brian Lavoie’s Introductory Guide. If you’re new to OAIS, I’d recommend that you at least read Lavoie’s report before tackling the full OAIS standard document (PDF).


{kind=link}